We have been using Amazon Bedrock for most of our enterprise workloads and we have been largely happy with it, decent model pool, security and compliance ready, easy to scale and deploy. Lately, newer models are dropped every week with better tokens per price and better benchmark scores. When the highest item in your bill is token usage, it's easy to get tempted to switch to a newer model. But it's not always the right or easiest decision.
Cost is the easiest axis to compare on. Benchmarks are the second-easiest. Neither one is the right switching decision for an existing application.
Price and benchmarks are the easiest to compare on
Both are general signals. The token price is real — input $/1M, output $/1M, every vendor publishes it. The benchmark score is real — MMLU, HumanEval, SWE-bench, every model has a number. You can compare them in a spreadsheet in ten minutes.
What these benchmarks don't tell you: whether the model works for your workload. Your prompts. Your data shape. Your guardrails. Your downstream consumers. Your latency profile in your deployment region. Your specific failure modes.
A model can be cheaper on tokens, better on benchmarks, and still fail your specific use case in ways the comparison can't see.
What switching actually costs beyond tokens
The hidden line items behind a model migration:
- Validating parity on your production data, not benchmark data.
- Re-tuning prompts. Prompts are model-specific. A prompt that works on Claude Haiku may underperform on Mistral, Llama, Gemma, or Nova — and vice versa.
- Re-validating guardrails. Refusal patterns, instruction-following, and jailbreak resistance vary across models.
- Adding pre/post-processing. When the new model's output shape is inconsistent, you need wrapper code to make it usable. Less likely for models that support JSON output format.
- Re-running compliance and safety evals. What passed audit on Model A has to pass on Model B.
- Building a rollback path. When the new model misbehaves in production, you need a way out — roll-back knobs and feature flags.
- Team retraining on the new model's quirks. For example, Anthropic Claude uses the old Bedrock runtime whereas Grok 4.3 uses the newer Mantle runtime.

Each of these is real engineering work. None of it shows up in the per-token price comparison.
Application-specific evals are the answer
Every application has to build its own eval. Benchmarks are general numbers — they tell you a model's broad capability, not whether it works for your specific workload. The eval that decides a model switch is the one shaped by your data, your success criteria, and your existing guardrails.
A model can look excellent on benchmarks, on cost, and on latency, and still fail the application-specific eval — at which point all three of those wins disappear behind engineering work that wasn't in the comparison.
Note what a candidate model actually has to clear: not a benchmark average, but the production behaviour of a model you've trusted for two years. In our experience — and across the enterprise communities we engage with — Anthropic's Claude family has been one of the most production-stable model lines for sustained workloads. That stability is part of why so many teams sit on it long after newer models ship at lower headline prices. The new model has to match that earned reliability, not just look good on paper.
Lived practice: the eval tool we built
Last week, prompted by new models landing in AWS Bedrock — which now spans Anthropic Claude, Amazon Nova, Google, xAI, Moonshot, Z AI, and others — we built an in-house eval. It pulls random samples from our production data, runs them across a pool of candidate models, and generates a comparison report. We have been running Claude Haiku in production for almost two years; the eval is how we honestly check whether anything else has earned the switch.
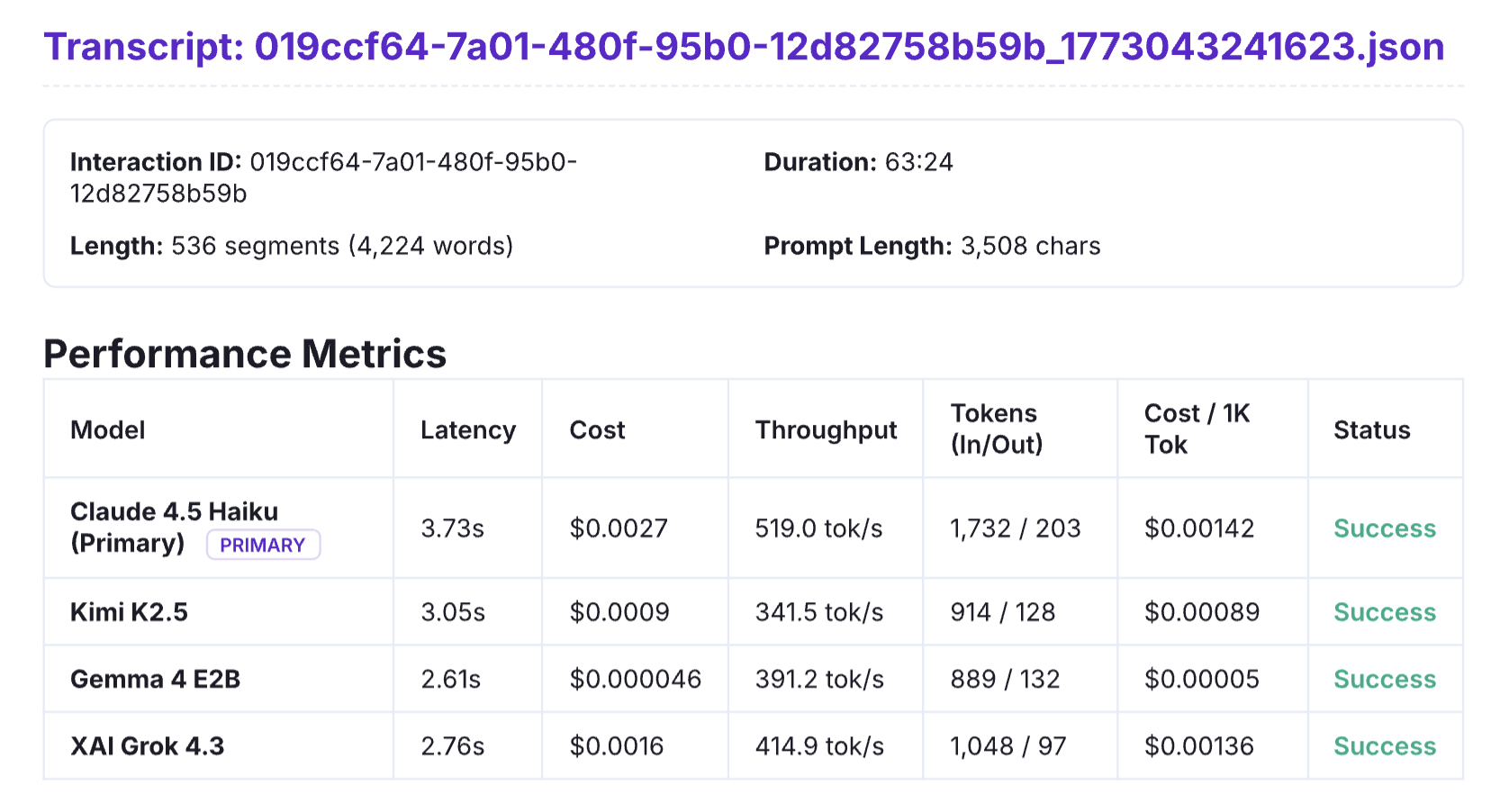
One concrete finding from our recent run: Gemma 4 is excellent on cost and latency — among the best on both axes in the candidate pool. But the output quality is not yet consistent for our specific workload. Making it usable would require non-trivial prompt re-tuning and additional pre/post-processing — engineering work that does not show up in the per-token price comparison.
That gap between looks good on benchmarks and works for our use case is what an application-specific eval surfaces and a general benchmark cannot.
When switching IS justified
Once parity is confirmed and guardrails preserved, then price matters. Or: when a candidate model offers a capability the current one doesn't — longer context, better function-calling, native multimodal, lower latency in a region you care about. Capability gains can justify a switch even at parity-only quality.
What you cannot do is switch on price alone, on benchmarks alone, or on vendor announcement alone.
Cost is the most obvious and visible reason to switch models. It is also the riskiest one to act on alone.